文章目录
一点背景
之前数据库课程的最后一次实验中有一项是验证数据库并发操作带来的问题以及事务的各个隔离级别对这些问题解决的程度,在测试过程中发现有些情况和课本的描述并不一样,一开始以为是隔离级别设置的步骤之类的出了问题,后来了解到其实各个数据库的实际实现都多少有自己对系统并发性能等方面的考虑,没有完全依照标准来完成。再之后在图书馆发现了一本讲 MySQL InnoDB 存储引擎的书,就仔细去了解了一下关于这个存储引擎的事务、并发和锁等方面的知识,同时看了一些 MySQL 的文档以及几篇博客,于是就自己对当时实验的用例进行修改设计了一些新的测试和验证代码,并把了解到的相关内容整理成了这篇文章。
准备工作
创建数据库和测试数据
DROP DATABASE IF EXISTS trans_test_db;
CREATE DATABASE trans_test_db;
USE trans_test_db;
CREATE TABLE demo (
id INTEGER NOT NULL AUTO_INCREMENT,
value INTEGER,
PRIMARY KEY(id)
) ENGINE = InnoDB;
INSERT INTO demo(value) VALUES (1), (2), (3);
创建测试用户
CREATE USER 'session1'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON trans_test_db.* TO 'session1'@'localhost';
CREATE USER 'session2'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON trans_test_db.* TO 'session2'@'localhost';
前面的这两个步骤用 root 或者其它高权限的账号操作,接下来就可以开始测试了,下面的代码全部使用刚刚创建完成的 session1 和 session2 两个用户完成。
注意为了测试事务的几种隔离级别及其影响,我们需要在一个用户的事务未完成(完成指提交/回滚)时切换到另一个用户进行其它操作,所以最好是直接在命令行输入代码进行测试,并且开启两个终端分别登录这两个用户以便于切换,这里顺手安利一个比较好用的 SQL 命令行操作工具 mycli。
设置测试环境和隔离级别
USE trans_test_db;
SET SESSION innodb_lock_wait_timeout = 3;
-- It is strongly recommended to reset(DROP & RE-CREATE)
-- the database before starting a new test session
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- OR:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; -- OR:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- OR:
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
上面这些设置需要在两个打开的 MySQL 客户端中都执行,保证测试的时候两个用户都是在同一个隔离级别下。修改了 timeout 值是因为操作过程中涉及到一些锁的超时验证,为了节省时间便把这个等待时长设置得短了一些。然后设置隔离级别时因为会对数据进行修改等操作,建议是一次测试完一个隔离级别的所有情况然后用最开始的建库代码重建数据库,重新开始新一轮的测试。
这里用的设置全部是 SET SESSION 而不是 SET GLOBAL,所以更改仅会对当前会话产生效果,不用担心影响到其它数据库、终端或者用户。
并发带来的问题
为了方便更加直观地查看模拟两个并发事务的 SQL 代码,这里用图片的方式来展示它们。
我们通过刚刚打开的两个终端,分别模拟两个事务执行,左右两边分开的代码分别代表两个事务的执行内容和顺序,从上至下进行。注意不要一次把一个事务的操作全部执行完了,而是应该按照整体的上下顺序切换命令行进行操作。
丢失更新
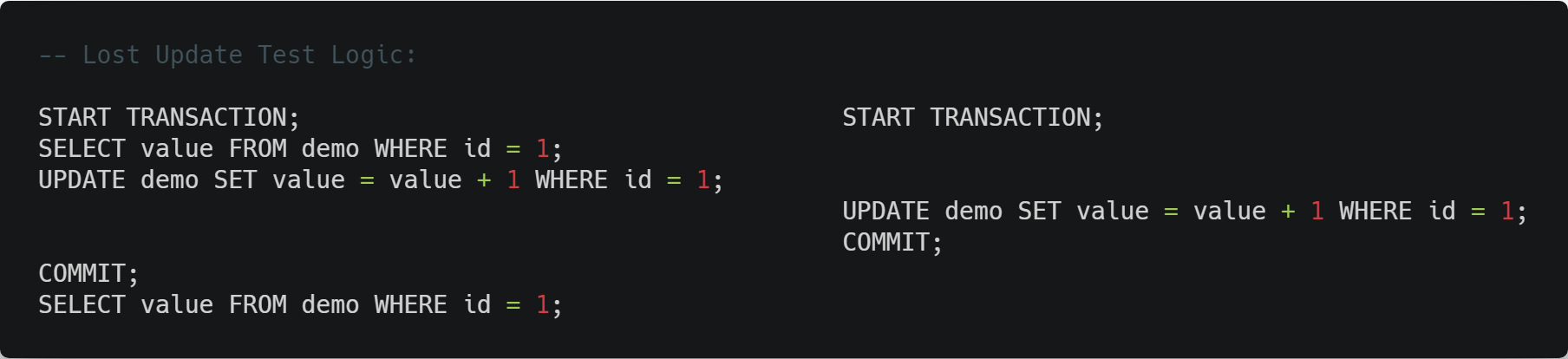
数据库意义上的丢失更新其实很多时候都不被当作并发带来的问题之一,因为更新操作在任何的事务隔离级别下都会加排他锁,在提交事务之前可以避免其它事务对当前事务所修改值的更新操作。测试的时候会发现哪怕是使用隔离级别最低的 READ UNCOMMITED,在事务二中执行 UPDATE 时都会抛出锁等待超时的错误:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
但是要注意的是,这里说的是“数据库意义上”的丢失更新不会出现,即不会出现一个事务对某数据的修改还未完成时,该数据的值就被其它事务更新覆盖了的情况。实际的业务环境中,如果用以上写法还是会有可能导致丢失更新问题出现,比如想象一个情景,两个事务都根据 SELECT 语句取出的值去进行操作,事务二在事务一更新前拿到了这个值,然后事务一进行了更新后提交事务,此时事务二用这个旧的值执行增减操作然后更新提交,没有出现数据库层面上的丢失更新问题,并发也没有锁的冲突,但是事务一的更新确实被事务二的覆盖了。
这种情况要解决,一般来说代价最小的方案就是在查询时说明这份数据将会被更新,禁止其它事务进行查询操作,也就是锁定读(SELECT ... FOR UPDATE等)。这个时候如果其它事务进行普通的 SELECT 操作,仍然能得到它的值,但如果是另一个需要更新它的值的事务进行 FOR UPDATE 的查询操作时,会抛出和上面一样的锁等待超时错误。
事务一的 COMMIT 之后有一行查询语句,这个是不需要手动再提交一次的,因为 InnoDB 引擎默认将没有显示指定事务开始(START TRANSACTION/BEGIN)的单条语句都当作一个事务来执行,这个开关可以通过 SET autocommit = {0 | 1} 来手动修改。
脏读
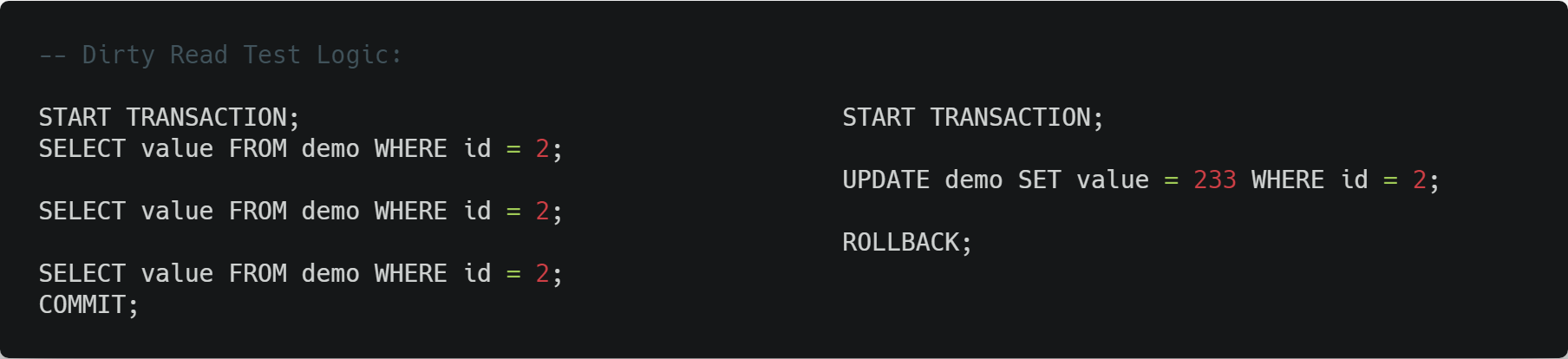
如果确实不把丢失更新当作数据库并发带来的问题的话,脏读是最低级的一个问题了,它对应事务隔离级别中的 READ UNCOMMITED 级别,测试中可以发现除了这个级别以外,其它三个隔离级别下都不会出现在事务一中读到事务二提交之前的修改结果的情况,即三次 SELECT 操作读到的都是同一个值。
脏读的主要麻烦点在于读到的数据有可能是在数据库中从来没有存在过的,所以除了那些对数据准确性要求不高的业务以外,一般都不太会使用 READ UNCOMMITED 级别。
不可重复读
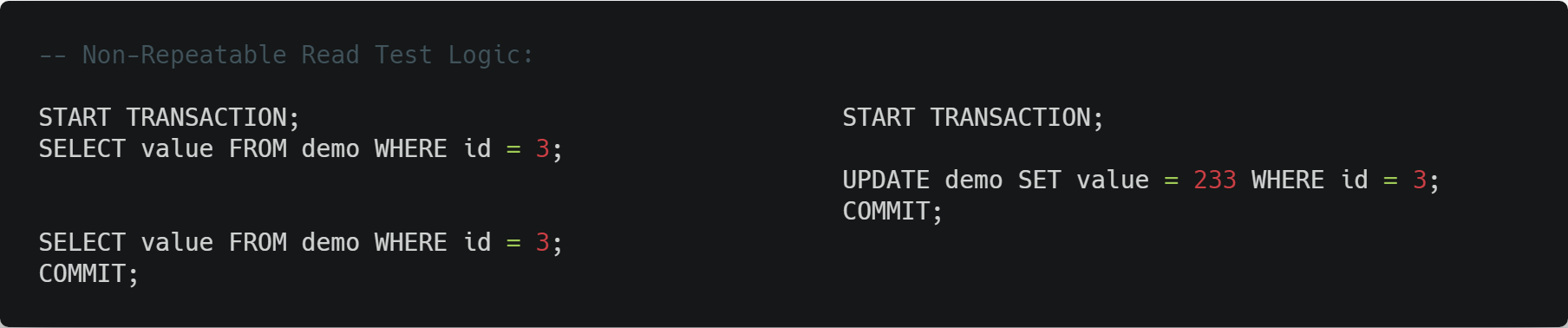
在事务二对事务一中已经查询过的数据进行更新操作后,如果事务一在提交之前再次进行相同的查询得到的结果和上次不同,那么就产生了不可重复读的问题。
不可重复读对应的是事务隔离级别中的 REPEATABLE READ,也就是前两个隔离级别(RU、RC)会有不可重复读的情况出现,而后两个隔离级别(RR、SZ)可以解决不可重复读的问题。
幻读

事务一使用某个条件查询一个集合,之后事务二向数据库插入了一些新的符合这个查询条件的数据,于是当事务一再次查询时会发现返回的集合比上次的数量要一些,就像查询操作产生了幻影(Phantom)一样。
本来按照 SQL1992 标准的话,RR 级别下是会出现幻读的问题的,这个问题仅在 SERIALIZABLE 级别下才会被解决,但是测试的时候会发现这个问题和前面的不可重复读一样,在 RU、RC 级别下会出现,而在 RR、SZ 级别下并没有,后面会谈及具体原因。
在《MySQL 技术内幕:InnoDB 存储引擎(第二版)》的 6.5 锁问题 一节中把不可重复读和幻读混为一谈了,个人感觉这是不太合适的,毕竟本身不可重复读和幻读就被定义为两个不同的并发执行问题,而且它们的侧重点也不同:虽然看起来都是事务一两次查询然后中间由事务二进行一次数据库的增改操作,最后导致两次查询的结果不同,但是不可重复读是由 UPDATE/DELET 导致的两次查询结果不一致,而幻读是由 INSERT 导致的,这两种情形在实现上就是不同的情况了,毕竟对已经在数据库的数据可以直接进行加锁,而阻止其他事务插入满足一个查询条件的数据,其实现代价和运行开销都是很不一样的。所以尽管两个问题在概念上都是不可复现第一次查询,但后者会被单独拿出来看待。
关于不可重复读和幻读两个问题的更多讨论和解决方案,会在下文中提到,因为 InnoDB 对它们的实现涉及更复杂的数据库并发控制技术。
简单整理
RU(READ UNCOMMITTED)、RC(READ COMMITTED)、RR(REPEATABLE READ) 和 SZ(SERIALIZABLE) 四个隔离级别一级比一级严格,一般情况下隔离级别每严格一级可以依次解决脏读(Dirty Read)、不可重复读(Non-repeatable Read)和幻读(Phantom Read)现象。
InnoDB 实现了 SQL:1992 标准中定义的上述所有四种隔离级别,按照其定义,四种隔离级别下并发执行时可能出现的情况列表应当是这样的:
| Isolation Level | P1 ("Dirty read") | P2 ("Non-repeatable read") | P3 ("Phantom") |
|---|---|---|---|
| READ UNCOMMITTED | Possible | Possible | Possible |
| READ COMMITTED | Not Possible | Possible | Possible |
| REPEATABLE READ | Not Possible | Not Possible | Possible |
| SERIALIZABLE | Not Possible | Not Possible | Not Possible |
但是上面提到,实际上在测试过程中会发现 InnoDB 引擎的 RR 级别已经没有了幻读(即表中 P3)的问题,然而事务二中的数据又是确实存储进了数据库的,这是因为 MySQL 的这个存储引擎用 MVCC 来保证了在 RR 级别下的一致性读,这样的话 REPEATABLE READ 就和 SERIALIZABLE 在效果上基本相同了,除了后者会对事务中的 SELECT 语句自动加上锁,参考其 官方文档 中给的说明:
SERIALIZABLE
This level is like
REPEATABLE READ, but InnoDB implicitly converts all plainSELECTstatements toSELECT ... FOR SHAREif autocommit is disabled.
算是功能的实现者在完全遵循标准和提高系统性能之间做的一个权衡吧,毕竟隔壁 Oracle 数据库甚至只实现了三个事务隔离级别呢(。也正是因此,MySQL 中的默认事务隔离级别是 RR,而不是其他数据库常用的默认 READ COMMITTED。
多版本并发控制(MVCC)
在谈及 MVCC 之前,先来看看针对幻读问题的一个额外测试:
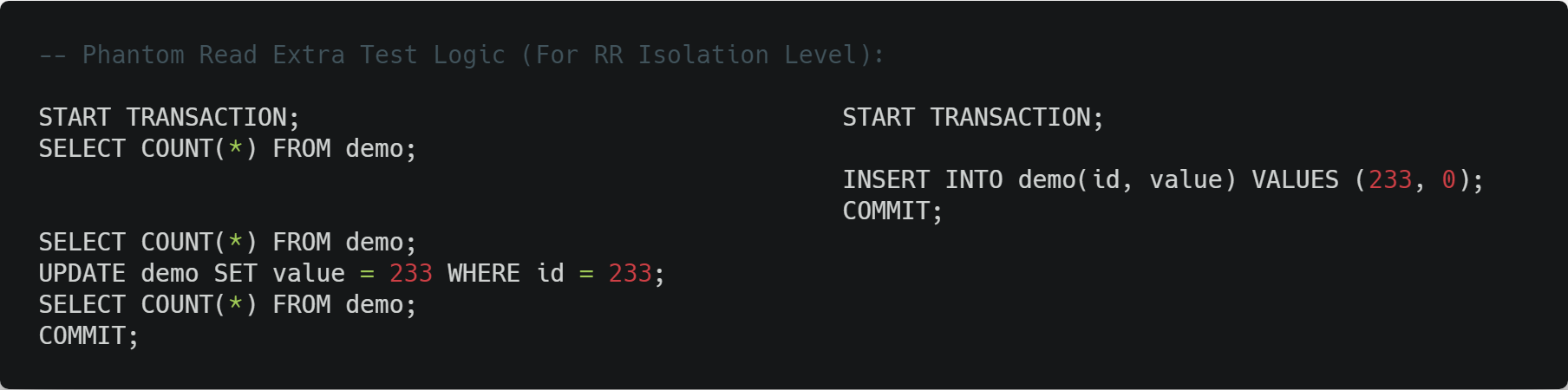
在 RR 级别下,按顺序执行这些操作,会发现第一次和第二次的 SELECT 结果是相同的,而在事务一中更新那个“不存在”的行后,再次执行第三次 SELECT,会发现这个新的行又突然出现了,这说明事务二的插入数据操作确实是影响到了数据库中存放的内容的。
MySQL 官方文档的 一致性非锁定读 中有对这个情况做出解释,大致意思就是一致性读会使用多版本的并发控制方式让事务读取一个快照以保证每次读取的数据一致,但是如果事务中有对这些“不存在”的数据进行更新等操作就是例外情况了,这个条件下事务就能在之后的查询中看到这些数据。
一致性非锁定读是指 InnoDB 通过 MVCC 的方式保证每次读取都返回某个时间点的数据,用以保证数据查询的一致性,它是 READ COMMITTED 和 REPEATABLE READ 两个隔离级别对 SELECT 进行操作的默认处理。不同的是,对于 RC 级别,读取的快照是每次执行查询操作时产生的,而 RR 级别读取的快照是事务开始后的第一次查询操作产生的,我们也可以在开始事务时加上 WITH CONSISTENT SNAPSHOT 修饰符来保证读取的是进入事务最开始时的快照。
“非锁定读”意味着读取操作不需要对数据进行加锁,因为它读取的是快照中的数据,而快照中的数据是不可能需要修改/删除等操作的,它只是相当于一份历史记录而已。
InnoDB 对每行数据增加了事务 ID 的字段,用于存储最后对其进行操作的事务,并有一个回滚指针指向操作对应的 undo record,并且在多版本并发控制的情况下,行中还有一个删除标记用于记录数据是否被删除,这样可以让数据不被实际物理删除,以保证其它事务不会突然读取不到某条数据。
MVCC 的实现主要依赖 undo log,而这个 log 本身又被用于数据库的事务回滚操作,所以通过这样的方式实现的多版本并发控制仅需极小的额外开销。
行锁的算法
最后非常浅显地谈谈 InnoDB 中几个常用锁的算法。
针对行记录的锁,我们可以使用 Record Lock、Gap Lock 和 Next-Key Lock 三种算法:
- Record Lock:针对单行记录的锁
- Gap Lock:锁定一个范围
- Next-Key Lock:锁定记录及记录前的一个范围,即 Record Lock + Gap Lock
具体举例来说,如果数据库中目前有 id 分别为 1,2,5,6,7 的五条数据,并且有给这个列创建索引,那么我们使用一个 WHERE id = 5 的锁定读,Record Lock 锁定的是 id = 5 的记录,Gap Lock 锁定的是 (2, 5) 这个区间,而 Next-Key Lock 锁定的便是 (2, 5] 区间了。
InnoDB 正是使用了 next-key locking 的方法,在 RR 级别下如果使用了锁定读,便可防止其它事务向该区间插入数据,从源头上解决了幻读的问题,也就是说这个解决方案并不是 MVCC 那种用快照和行记录中的事务 ID 先后顺序判断的方式“隐藏”了新插入的数据,而是直接用锁禁止掉了其它事务的 INSERT 语句的执行。
对这几个锁的实际测试这里没有整理出 SQL 代码,因为涉及到了一些关于索引是否为唯一索引、锁降级、辅助索引等内容,想等之后把详细内容整理好并进行测试和验证,作为另一篇单独的文章发出来。
主要参考资料
- MySQL技术内幕:InnoDB存储引擎
- 『浅入浅出』MySQL 和 InnoDB
- The basics of the InnoDB undo logging and history system
- Isolation (Database Systems)
- MVCC(Multiversion concurrency control)
- MySQL 8.0 Reference Manual
文中的所有 SQL 测试代码都整合好放在了 Github 上,演示用代码的图片是用 carbon 生成的。