文章目录
这篇文章算是上一篇 整理和分享一些数据结构作业用到的 LaTeX 排版技巧 的一个补充,主要的区别在于数据库课程是用中文上的,加上要交的题目类型还是有些区别的,所以作业的内容排版上就不同了,因为数据结构作业排版的那篇文章已经把大部分的内容讲掉了所以这里就只说那里面没提过或者相对它有较大修改的部分。
基础内容
封面
封面的结构和数据结构作业用的基本是一样的,不过因为内容里有中文,需要使用中文的 TeX 环境,并且设置文档编码为 UTF-8 以避免构建出来的文档乱码,这些改变只需要把原来的 \documentclass[titlepage]{article} 改成 \documentclass[UTF8,titlepage]{ctexart} 即可:
\documentclass[UTF8,titlepage]{ctexart}
\title{Database Homework 1}
\author{Kingsley}
\date{\today}
\begin{document}
\maketitle
\clearpage
\tableofcontents
\clearpage
\end{document}
段落层次
有时候我们可能需要调整部分内容是否在目录页进行展示,这时候可以通过 \setcounter{} 命令来指定,tocdepth 的值指定目录层将显示到哪一级为止,secnumdepth 的值指定层级的编号到哪一级为止,比如这样的一个文档:
\documentclass[titlepage]{article}
\setcounter{tocdepth}{2}
\setcounter{secnumdepth}{5}
\begin{document}
\tableofcontents
\section{Section}
\subsection{Subsection}
\subsubsection{Subsubsection}
\paragraph{Paragraph}
\subparagraph{SubParagraph}
\end{document}
tocdepth 是 2,对应 article 文档里的 subsection 层,而 secnumdepth 是 5,对应 subparagraph 层,(下面简写成 (2, 5))显示出来的样子就是目录上到第二级为止,而编号到第五级为止:

如果去掉这两行的话,默认的显示是 (3, 3) 的值的效果:

如果是 (5, 2) 的话,展示出来的就是目录中显示了五级但是编号只到第二级为止:

顺带一提这里是 article 而不是刚刚说的 ctexart了,两者对部分内容的居中方式有一点区别,不过不影响这里的演示就不管啦。
(写了三个示例其实主要是为了方便自己以后记不清的话可以来这里看图片想起来2333)
这个设置其实我自己用到的场景是这样的:大部分时候作业的题目是不按顺序的,那我可能得把题号写进 section 的文本里面,但是这样的话编排出来会导致题号的数字前面又有一个编号,看起来会有点乱,所以在这种情况下就直接用 \setcounter{secnumdepth}{0} 来直接去掉了所有标题级别的自动编号。
超链接的红色外框
这个其实很简单了,应该刚开始用 LaTeX 的时候都会碰到所以上次写的时候就没提,这里因为刚刚有提及目录以及后面有用到个图片引用的功能就顺带提一下。
默认生成的任何文档,比如我们刚刚生成的那个目录文档,里面的链接都是不可点击的,那么要让它们能够在点击后链接到对应的地址,可以通过引入 hyperref 包来达到目的,但是这样的话又会发现所有可以点击的文字都被加上了一个红色的外方框,很显然这可以让链接文字和普通文字区分开来,让阅读者知道那个地方是有链接的,但是有时候我们可能并不想让这个链接有这样的方框,讲道理很丑啊好不好,这个时候直接对它加上一个 hidelinks 选项即可,所以就是在文件引入 package 的代码部分加上这个即可:
\usepackage[hidelinks]{hyperref}
关系代数
数据库作业那肯定是免不了要写关系代数的,但是几个连接的符号又比较难搞定,在一番查找和对比之后发现了最简单的方式,就是使用 unicode-math 包,这样不仅连接符号可以轻松搞定,整个关系代数公式的排版都轻松了很多,不过缺点就是它还不支持在公式里面放中文,所以我当时是用拼音代替的。
默认的那个字体其实很难看,可以通过 \setmathfont{} 来换一个看起来舒服一点的字体,我个人是用的 Asana Math,然后还要注意的一个地方是因为我平时使用的是 pdfLaTeX,但是这个 unicode-math 是得用 XeLaTeX 去 build 才能使用的,直接在文件的开头加上一行指定类型的代码即可,顺便吐槽一下这个 XeLaTeX 的构建时间真的是巨长,不知道是不是我的使用姿势不太对。
最后的示例文件内容看起来大概是这样:
% !TEX program = xelatex
\documentclass[UTF8,titlepage]{ctexart}
\usepackage{unicode-math}
\setmathfont{Asana Math}
\begin{document}
$\pi_{JNO}(SPJ) - \pi_{JNO}(\sigma_{CITY='CT' \land COLOR='CL'}(S \Join SPJ \Join P))$
\end{document}
效果好像还是可以的:
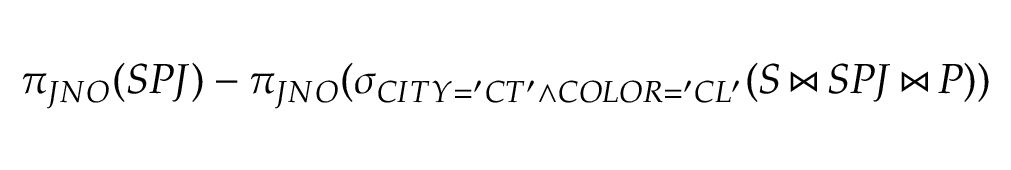
左右连接和全连接符号分别是 \leftouterjoin、\rightouterjoin 和 \fullouterjoin,更多其它符号可以在 unicode-math 包的 文档 中找到。
SQL 代码
代码环境的常见用法和配置之前那篇文章已经提了很多,所以这里就不赘述了,只说几个和 SQL 代码显示相关的问题。
首先就是如果 SQL 代码里面包含单引号,就会无法正常构建,这个问题直接通过引入 textcomp 包即可解决。但是其实在渲染的效果上会发现这个引号并不是竖直的那种适用于代码显示的格式,我们可以在 \lstset{} 里指定 upquote=true 来让这个引号看起来更舒服一点。
另一个常见的情况是我们希望把 SQL 代码中的某个词高亮,当然办法有很多,这里只说一个通过嵌入 LaTeX 命令的实现方式,同样需要在 \lstset{} 里设置,语法是这样的:escapeinside={\%*}{*)}。前后两组大括号内分别是自定义的起止分隔符,这样我们就可以在 %* 和 *) 内通过 \textbf{} 来让某部分显示粗体了:
\documentclass[UTF8,titlepage]{ctexart}
\usepackage{listings}
\usepackage{textcomp}
\usepackage[T1]{fontenc}
\lstset{
basicstyle=
\def\fvm@Scale{0.8}
\fontfamily{fvm}\selectfont,
upquote=true,
escapeinside={\%*}{*)},
}
\begin{document}
\begin{lstlisting}
SELECT * FROM users WHERE username = 'admin'
SELECT * FROM users WHERE %*\textbf{username}*) = 'admin'
\end{lstlisting}
\end{document}
注意那个起始符的百分号在设置里是要转义的,但是在代码里不需要转义,生成的效果是这样:

E-R 图
E-R 图是数据库作业排版里面的一个相对比较棘手的问题了,不用说都知道这种复杂图形绘制的纯 LaTeX 解决方案得往万能的 tikz 那边去考虑,查了查发现还真有个 er 的库用来画 E-R 图,不过说实话个人感觉并不是很好用。
使用 tikz 解决
在 TeXample 网站上找到了两个方案,一个是别人自己修改样式后的版本:Example: Entity-Relationship diagram,另一个是直接使用 er 库来完成的稍微没有前面的那么华丽的版本:Example: Entity-relationship diagram。
我用的是后面的一个方案,然后自己加了点 \tikzset{} 的设置让每个节点看起来有比较统一的宽高,代码就不贴在这里了,可以在 GitHub 上查看,\node[attr] 里的 attr 为 entity 和 relationship 时分别代表这是一个实体和关系,然后对它进行一个命名方便其它节点可以用 [below of=name] 之类的方式来定义自己相对它的位置,并且用这种方式定义好自己相对另一个节点的位置,以及节点的文本内容,最后加上边、边上的数字和方向以及边所指向的节点,看起来也算是挺直观的,很容易理解并且魔改成自己的,但是最后排出来的效果并不怎么样。
更方便的解决方案
用 tikz 来画比较复杂的图的话,要达到自己想要的效果其实是需要不少时间的。主要的问题在于,一方面学习成本比较高,还得花蛮大的精力去调整宽高这些属性的统一程度的问题,特别是遇到需要一定时间来构建的图的话等待起来会让人很烦躁,另一方面是如果碰上需要修改结构之类的情况,工作量确实不小,所以比较推荐使用 drawio 之类的网站画好图然后选中那个区块导出成 PDF,再嵌入 LaTeX 文档:
\begin{center}
\includegraphics[width=0.7\textwidth]{filename.pdf}
\end{center}
通过这种方式,从最终效果上看生成的文件还是一样可以选中文字和整体矢量放大,但是无论是生成图片还是增加节点、修改结构都方便了很多,并且远不止适用于 E-R 图这一项,只要网站能提供或者使用者能画出来的任何图都可以用这种方式完成,生产力 MAX。
可选的 width 选项指定插入图片的宽度,如果不设置的话碰到稍大的图片就很容易会排错乱掉,比如图片的宽度超过了文档的最大宽度的情况。width=\textwidth 表示图片宽占满文档的最大宽度,通过在它的前面加某个数字即可调整图片的显示规模。
查询树图和关系代数语法树图
因为这两种树的特性,不用像每个节点最多有两颗子树的二叉树一样去考虑给空缺的一边占位,所以可以直接用数据结构作业时画普通树的 forest 包来排版,只是这颗树不需要给节点加外框之类的,而是直接的文本或者公式了。
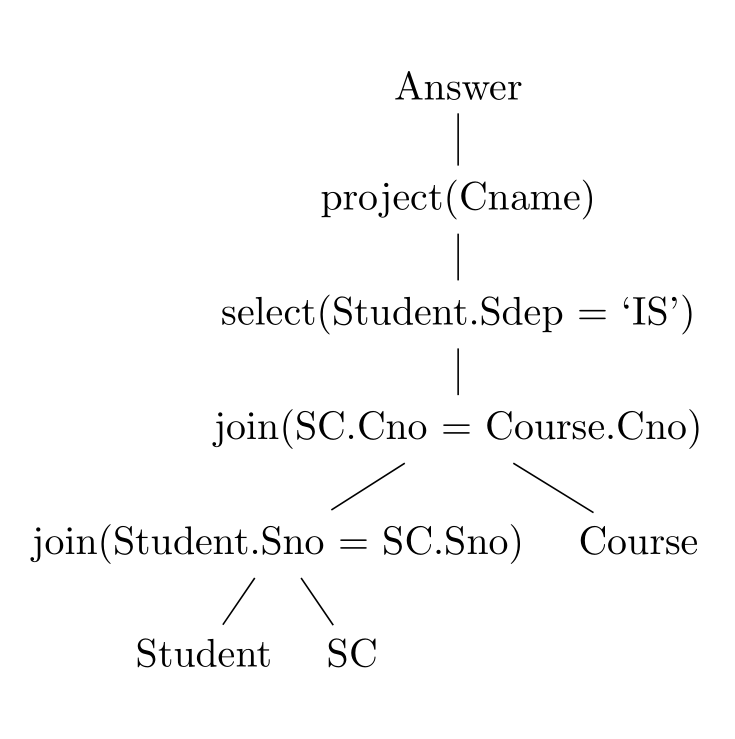
查询树
\begin{forest}
[, phantom, s sep = 1cm
[Answer
[{project(Cname)}
[{select(Student.Sdep = `IS')}
[{join(SC.Cno = Course.Cno)}
[{join(Student.Sno = SC.Sno)}
[Student]
[SC]]
[{Course}]
]
]
]
]
]
\end{forest}
语法和格式上基本上和前篇文章讲的用 forest 包排版普通树的是一样的,不过它的节点毕竟不是数字了,而且包含了等号空格之类的特殊字符,所以要用一对大括号括起作为一个文本,这段代码对应效果如下:
关系代数语法树
相对查询树的主要的区别是有些操作的文本被替换成对应的关系代数了,那么就得用前文所说的关系代数的排版方式放进数学公式的环境里:
\begin{forest}
[, phantom, s sep = 1cm
[$\pi_{Cname}$
[$\sigma_{SC.Cno\,=\,Course.Cno}$
[$\times$
[$\sigma_{Student.Sno\,=\,SC.Sno}$
[$\times$
[SC]
[$\sigma_{Student.Sdep\,=\,'IS'}$
[Student]
]
]
]
[{Course}]
]
]
]
]
\end{forest}
有几个微小的细节,首先是为了整体的统一,应该把所有的节点都各自放进数学公式环境中($Node Text$),不然关系代数节点和纯文本节点的字体不一样看起来就有点不爽(
其次是关系代数的等号前后应该略留空隙,这里直接使用 \, 的方式来作为占位空格了,注意如果是直接的空格字符的话渲染出来的等号左右两边是直接和等号相连没有间隔的。
最后就是对比查询树会发现两份代码中对 IS 字符的引号是不同的,在数学环境下用的是直接的两个字符作为引号,而文本环境中用的是 LaTeX 给普通文本环境用的的标准引号对 `'。
如果引号的使用反过来的话,前者输出的将会是 ’IS’ 而不是正确的 ‘IS’,后者输出的将会是 ‘IS' 而不是正确的 'IS'(准确说那个其实好像也不是单引号 反正就是看起来类似它的一个符号 这里就不深究了)。
最后给上这个关系代数语法树的效果图:
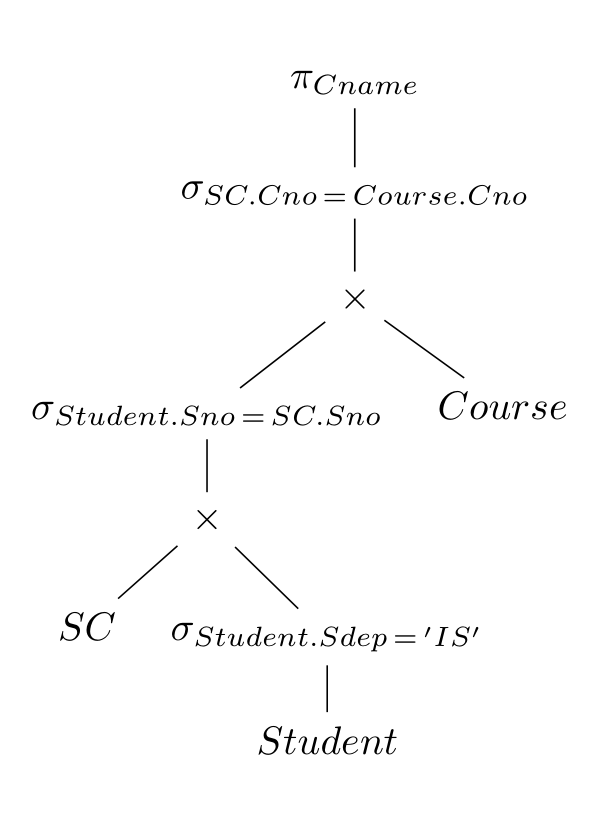
figure 环境
这个东西展开讲肯定是内容超多的,这里仅仅带过和本文相关的一个部分,就是对如何把前面的几份图片放进 figure 环境的一点简要整理。
对于 tikzpicture 我们可以这样把它居中作为图片放进去:
\begin{figure}[!htb]
\begin{center}
\begin{tikzpicture}
blabla
\end{tikzpicture}
\caption{E-R Diagram}\label{fig:er-diagram}
\end{center}
\end{figure}
当然对于刚刚提到的 forest 也是一样的,把里面起止的两个 tikzpicture 改成 forest 就行了,这里嵌套了一个 center 环境用于直接让图片水平居中。
\caption 一行指定该图的名称为 “E-R Diagram”,LaTeX 会按照图片在整个文档中的顺序进行自动编号,其中 \label 里面定义的值让这张图片可以出现在插图列表里面,并且可以在文档的其它地方通过 \ref 命令引用该图片:
\begin{document}
\listoffigures
\section{E-R 图}
如下图 \ref{fig:er-diagram} 所示。
\begin{figure}[!htb]
blabla
\caption{E-R 图}\label{fig:er-diagram}
\end{figure}
\end{document}
最终的图前文字显示是 “如下图 1 所示”,即 LaTeX 会自动找到这个文本对应的图片并将其编号渲染出来,如果加上前面提到的链接的设置的话,这个 ref 命令的引用处就可以点击跳转到对应的图片位置了,完整的代码和 PDF 文件参考 Repo,这里也不给了。
最后,图片的排版可能出现一个问题,就是文字明明写在图片的前面,却被排版到了图片之后,通过引入 flafter 包可以解决这个问题:
\usepackage{flafter}
源文件相关说明
所有的代码和对应生成的 PDF 文件都放在了 GitHub 上,不过 Repo 里的代码有些是用的另一个 documentclass:
\documentclass[tikz, border={5pt, 15pt}]{standalone}
这是为了能直接让生成的 PDF 仅有必要的留白(这里设置的是上下 15pt,左右 5 pt),而不是默认的 A4 之类的大小,因为用于演示的代码生成出的内容仅占一小部分,剩下一大片空看起来就有点难受。
延伸参考
(前三个复制粘贴自上篇文章,因为感觉这段还是挺有价值的,第四个是新补充的)
CTAN
这里收录了大部分的 TeX 包以及他们的 README、官方文档等内容,非常详尽。在我感叹tikz这个包怎么功能这么强大的时候,我找到了这个包的 文档,然后就……emmmShare LaTeX
这个网站本身是用于在线合作编写 LaTeX 文档的,他们提供的这个learn部分感觉对于学习 LaTeX 很有帮助。我记得我高中的时候也有了解过这个网站,因为当时它给的 Demo 里有一张青蛙的图片,让我印象很深刻(WikiBook
搜索结果里经常也看到来自这里的内容,不过我没太仔细了解,应该和上面的那个差不多。相对官方文档而言,这种整合并且带索引的结果可能有时候更符合我们的需求。TeXample
好像是在搜索怎么用tikz画 E-R 图的时候发现的?这个网站对每种样例都给出了详尽的 TeX 代码和它们对应的预览图、PDF 文件,所以可以很方便地直接尝试里面的各种样例去魔改。